
2009年9月7日のエントリー「XHTMLでなくHTML4.01を使うわけ」で、ユーザーエージェントとして普通のブラウザを想定した場合、XHTMLでは面倒が出ることはあってもメリットが享受できることはなさそうだ。
と書いたが、どうやらそれを撤回することになりそうだ。 そのきっかけになったのは、「楓駅の記憶」というサイトに収載した画像にクリエイティブ・コモンズのライセンスを付けようとしたことである。クリエイティブ・コモンズのサイトでは、かつてはRDFを埋め込むのにコメントを使用するという妙なことを推奨していたのだが、久し振りに見てみると、これがRDFaを使ったものになっていた。こういうメタ情報を文書に埋め込もうとすると、どうしてもXHTMLの出番になってしまう。
しかし、クリエイティブ・コモンズ謹製の埋め込み用コードは下位要素の中で名前空間を宣言していていまいち汎用性がないように感じてしまう。どうせRDFaを使うなら文書の他の部分にも適用してみたいと思った。そうするとhtml要素に対して名前空間を追加して宣言することになるし、そうできるのがXHTMLのはずなのだが、もう一つ気になることがあった。RDFaを使った文書の文書型がXHTML1.0 StrictやXHTML1.1のままで良いのかという疑問である。RDFaモジュールを加えた文書型はないのだろうか。 あちこち検索しているうちに、ミツエーリンクさんの「Web標準Blog」の2008年6月27日付の記事「メタ情報をXHTMLに埋め込むRDFa」を見つけた。同記事にはまだ勧告でないとあるが、その一方でRDFaが最近W3Cの勧告になったことが書いてある文書も容易に見つけることが出来た。しかし、どこをどうすれば意味のあるメタ情報になるのだろうか。
ここで指針を与えてくれたのが「The Web KANZAKI」にある「セマンティックHTML? KISS!」に紹介されているテンプレートだった。同サイト内の他の文書も参考に、「楓駅の記憶」のあるページをXHTML+RDFa文書に書き換えてみた。
しかし、XHTML文書をサーバーに上げるということになると、MIMEタイプの問題が出てくる。Internet Explorerはバージョン8になってもapplication/xhtml+xmlの文書を表示できないからである。application/xhtml+xmlの文書を受け入れないユーザーエージェントには従来どおりのtext/htmlを送ってあげないとならないが、その方法もウェブのあちこちに出ていた。その一つが「The Web KANZAKI」にある「今どきのXHTMLメディアタイプ」という記事で、問題点も含めて詳述されているが、当サイトにとっては問題にならないことばかりだった。
あと副次的な問題として昨今は文字コードはUTF-8の方が何かと都合が良いという点もあるのだが、検索エンジンのmsearchがEUC-JPを前提にしていることもあって今まで踏み切れずにいた。しかし、Unicode版のmserchもあるのであっさり解決。サイトを静的なページにしてから間もない時期ではあるが、「楓駅の記憶」の各ページをEUC-JPからUTF-8、HTML4.01 StrictからXHTML+RDFaにそれぞれ書き換える作業を開始したところである。モジュール同士を組み合わせているのだから、XHTMLは当然XHTML1.1相当になるが、それ以前に整形式であることが厳密に要求される。元々それは余り苦にならないし、HTML TidyのようなW3C謹製のツールを間に挟めば作業が大幅に楽になるので、雛形が出来さえすればそんなに手間ではない。
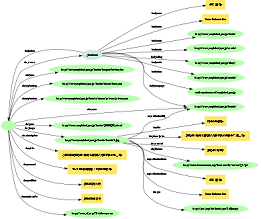
試行的に書き換えてみたページにメタ情報を埋め込んで「The Web KANZAKI」にあるRDFaの視覚化ツール(「ARC2によるRDFaとTurtleの視覚化」)を使うと、図のような画像が出てきた。また、文字コードをUTF-8にしてW3CのRDF Distillerを使うとRDF文書が取り出せた。
これは凄いことだと感心してしまう。ウェブサイトの管理をサボっていたこの数年の間に、少しずつでもいろいろ変わってきていることを実感した次第である。いまさらではあるが、どうやらXHTMLの価値を認めなくてはならなくなったようだ。自分で実験してみてはじめてそう思った。